Visualization Experiment

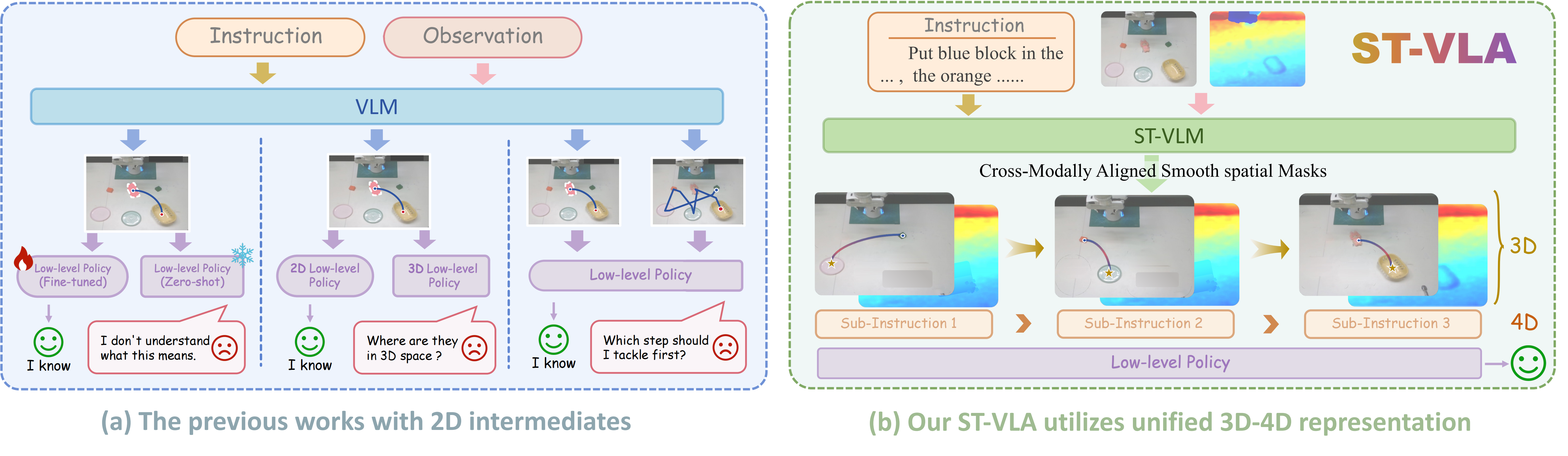
Robotic manipulation in open-world environments requires reasoning across semantics, geometry, and long-horizon action dynamics. Existing Vision-Language-Action (VLA) frameworks typically use 2D representations to connect high-level reasoning with low-level control, but lack depth awareness and temporal consistency, limiting robustness in complex 3D scenes. We propose ST-VLA, a hierarchical VLA framework using a unified 3D-4D representation to bridge perception and action. ST-VLA converts 2D guidance into 3D trajectories and generates smooth spatial masks that capture 4D spatio-temporal context, providing a stable interface between semantic reasoning and continuous control. To enable effective learning of such representations, we introduce ST-Human, a large-scale human manipulation dataset with 14 tasks and 300k episodes, annotated with 2D, 3D, and 4D supervision via a semi-automated pipeline. Using ST-Human, we train ST-VLM, a spatio-temporal vision-language model that generates spatially grounded and temporally coherent 3D representations to guide policy execution. The smooth spatial masks focus on task-relevant geometry and stabilize latent representations, enabling online replanning and long-horizon reasoning. Experiments on RLBench and real-world manipulation tasks show that ST-VLA significantly outperforms state-of-the-art baselines, improving zero-shot success rates by 44.6% and 30.3%. These results demonstrate that offloading spatio-temporal reasoning to VLMs with unified 3D-4D representations substantially improves robustness and generalization for open-world robotic manipulation.
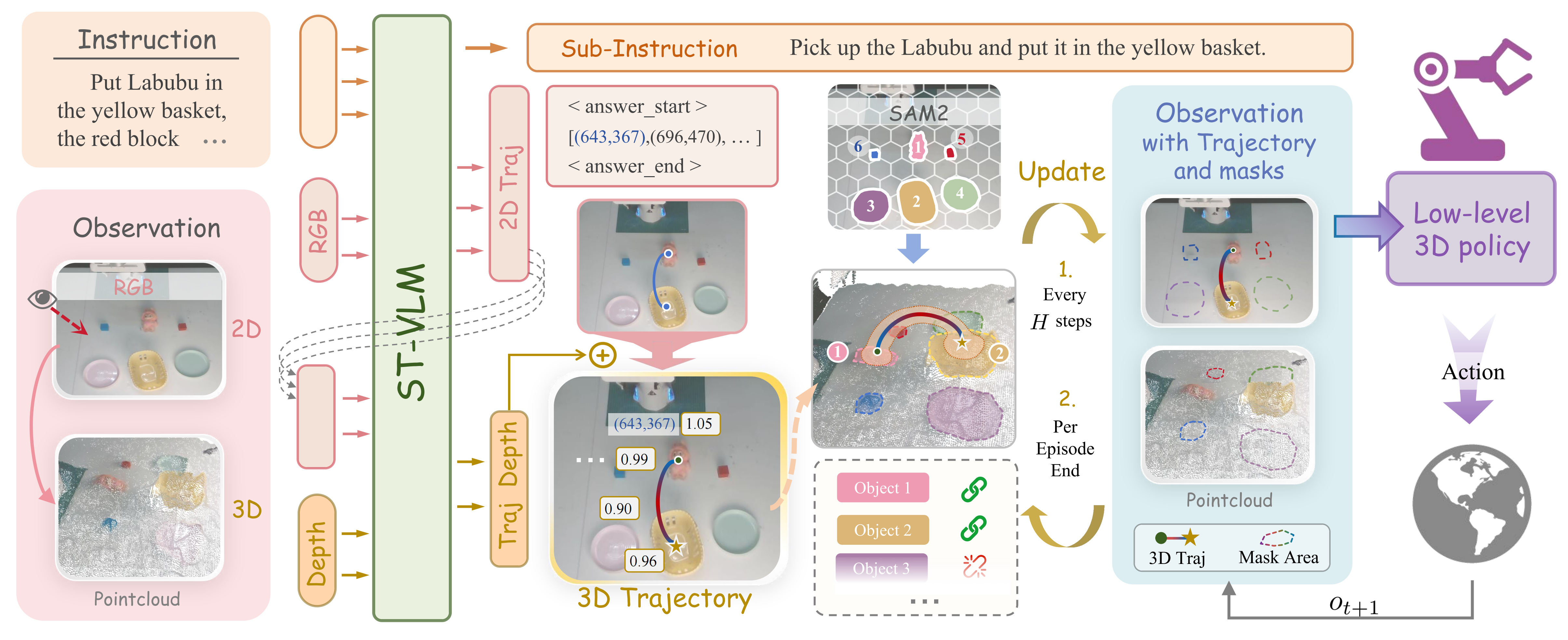
The ST-VLA Pipeline. Given a global instruction and an RGB-D observation, the high-level ST-VLM generates sub-instructions and 2D trajectories. These are lifted to 3D and fused with SAM2 masks to form a unified 3D-4D representation, which conditions the low-level 3D policy for continuous action execution. Guidance is refreshed every H steps for replanning and robustness to disturbances.
Overview of the ST-Human Dataset Construction and Unified 2D-3D-4D Task Generation.
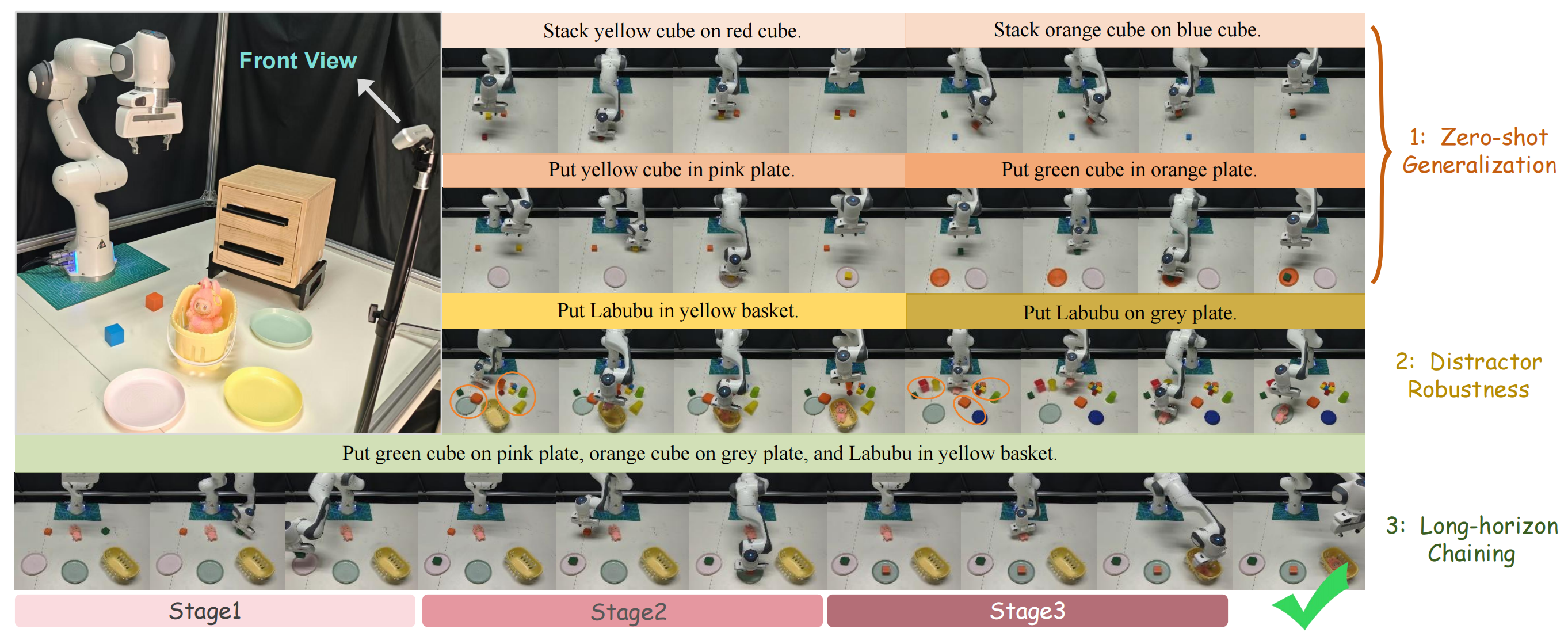
Setup & Tasks: (Left) Franka Emika Panda hardware setup. (Right) Qualitative results showing: (1) zero-shot generalization; (2) distractor robustness; (3) long-horizon chaining.
Performance: Real-world zero-shot generalization results.
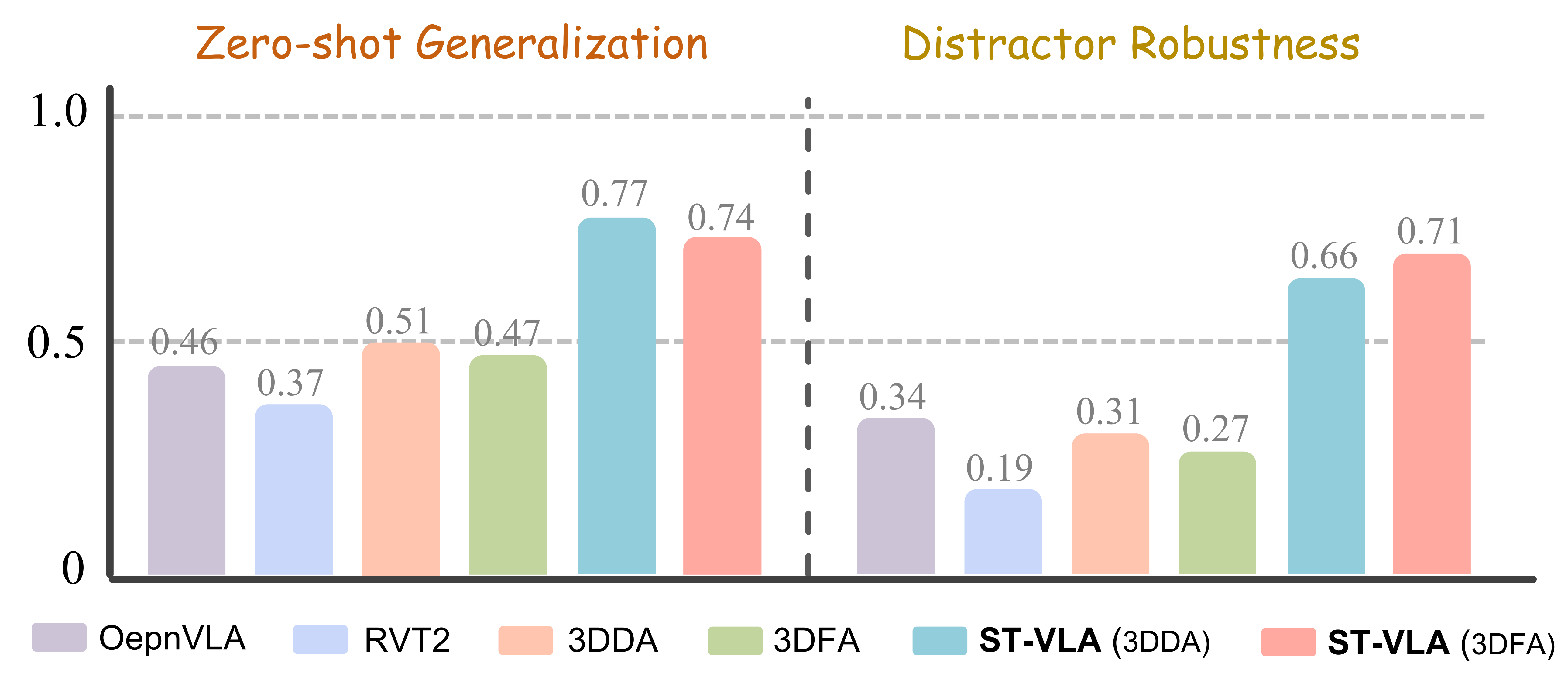
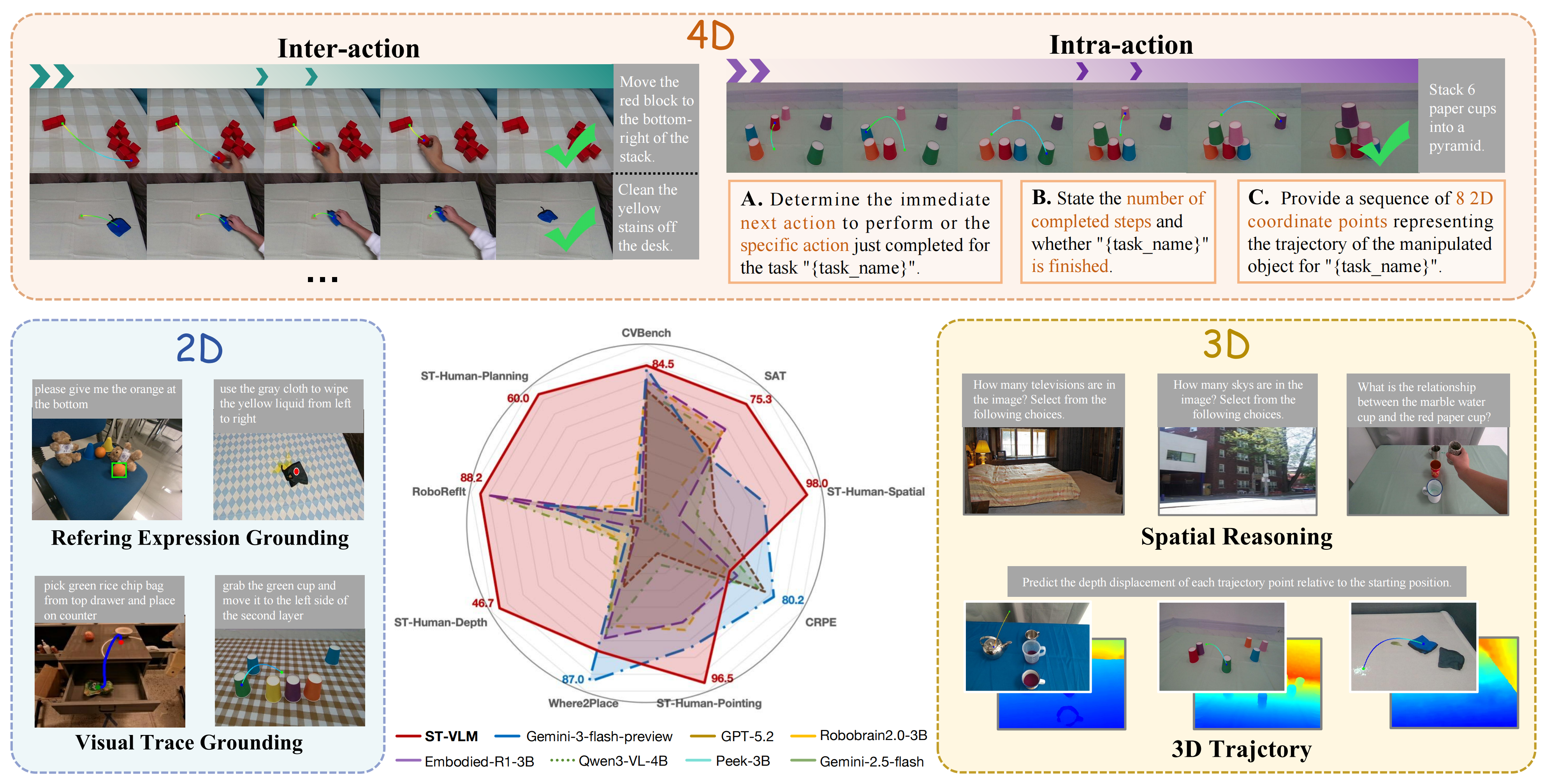
Table 1: VLM Performance Comparison on Selected 2D, 3D, and 4D Benchmarks. Best results are bolded.
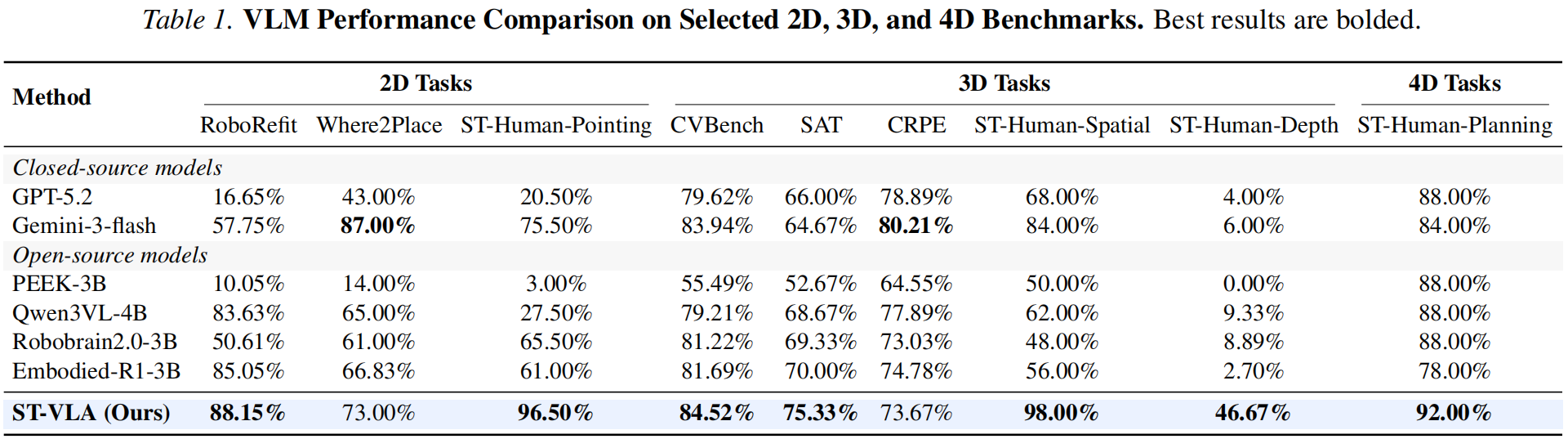
Table 2: Results on Simulated Robot Manipulation Tasks. Background colors highlight ST-VLA variants.
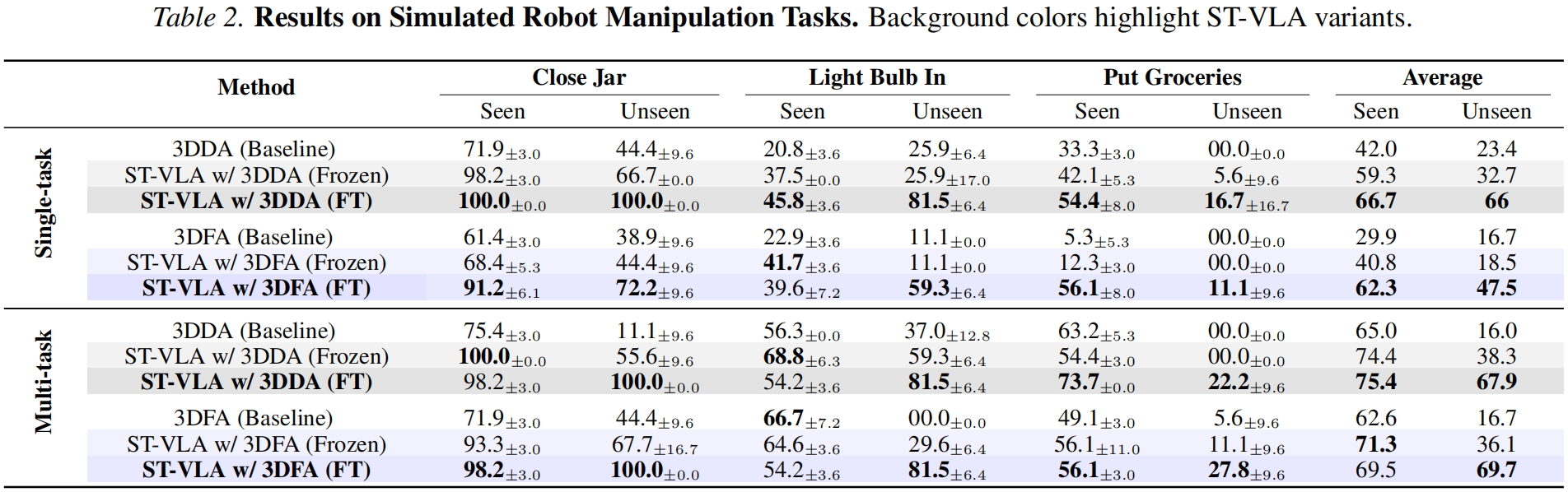
Table 3: Success rates on long-horizon push-button tasks across three seeds, evaluated ST-VLA(3DFA) on seen buttons and unseen multi-step sequences.

RGB
Depth
RGB
Depth